

By now, the problem is familiar: AI will write your research in minutes, but it cannot tell you which parts to believe.
The obvious way to fix unreliable AI research is to build better AI research. However, instead of joining the crowded, well-funded race of building bigger and smarter models, we built on top of them to make AI research more accountable, repeatable, and honest about where it is falling short. This is the story of SPARK – Self-verifying, Portable, Agentic Researcher Kit.
What does SPARK actually do?
It does three things your assistant alone will not.
-
SPARK scores every fact transparently, so you can see at a glance how far to trust each one.
-
SPARK remembers what it found, so research compounds across sessions instead of starting from scratch.
-
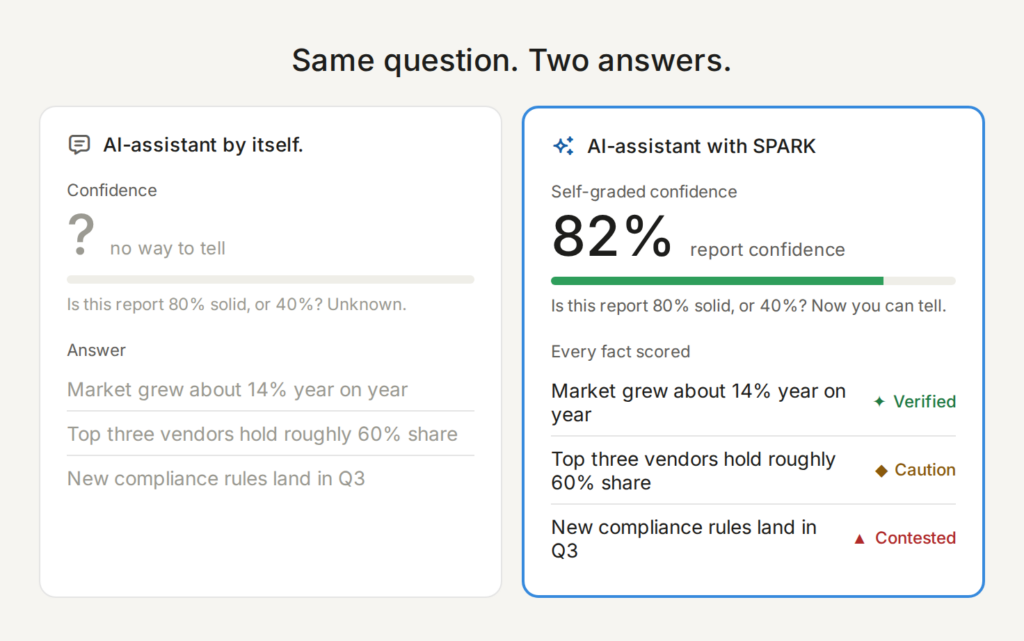
SPARK grades its own output, answering the question every leader actually has: “is this report 80% solid, or 40%?”
SPARK’s design directly integrates into your current AI research workflow so you do not switch tools, learn a new app, or go through a complicated installation process. You only need to add one line: the command, the research recipe, and the topic. That single line is enough to unlock claim verification, trust scoring, and memory.
First, you encode your research process into a recipe, so you can ensure the research goes the way your domain expertise guides it.
What is a recipe, and why does it matter?
Every serious domain already has experts who know how to conduct effective research within it, including what order to search, what to search for, and what counts as a credible source.
SPARK is designed to be domain-agnostic, and we made it easy to create a recipe. A recipe is a written research strategy that encodes these information into a form that an AI can follow. It runs the same way every time, rather than having the user improvise a fresh approach on each pass.
Our guided recipe creator tool walks any expert through turning their own procedures into a recipe by answering a few questions with smart defaults. Any field with experts and a method can have its own recipe, which automatically inherits the full verification, trust, and research-tracking layer.
How does it decide what to trust?
Every claim receives a trust score, which you can think of as the answer to five questions.
-
How inherently verifiable is the claim?
-
How many independent sources back it?
-
How reliable are those sources?
-
How fresh are they?
-
Is it contradicted anywhere?
Those roll into a single score, and each claim is tagged as verified, cautioned, or contested. Instead of a flat wall of confident text, you see at a glance which facts to lean on and which to dig into.
The contested tier is where SPARK behaves differently from a normal AI.
Imagine a model that identifies two sources that disagree: one reports 12% growth and the other reports 8%. Most AI tools resolve that conflict quietly by picking one or blending them into a single confident answer so the disagreement vanishes. That is more dangerous than outright fabrication, because the disagreement is a signal that there is more to the story. So SPARK does the opposite. It holds both numbers up, tells you they do not agree, and leaves the call to you.
Why does the tool need a memory?
Because research is a living thing, not a document you file once. The moment a report is finished, it begins to age, with no indicator for what still holds true. In fast-moving fields, a current claim can be out of date within a fortnight, and your stagnant previously-verified report is now wrong.
SPARK handles this with provenance and refresh. Provenance means every claim carries its own receipt so you or anyone else can audit any single fact instantly. Refresh allows you to automatically keep your research up to date; Come back a month later and ask SPARK what has changed. The tool tells you what is new, what is updated, and crucially, what newer sources now contradict. The research compounds across runs rather than resetting to zero each time.
Does it work?
In our own testing, deep-dive recipe runs returned no outright fabricated facts. We know this because we built a separate tool which tells us objectively the quality of our AI research outputs, including whether cited sources exist and whether each claim is genuinely supported by the source attached to it.
While embellishments are still another type of hallucination that needs to be tackled, SPARK does not claim to be error-free; its value is that the assessor shows you exactly where an error has crept in. We tested this deliberately on two different shapes of research, a structured market scan and an open-ended technology deep dive, and the same trust layer held for both.
SPARK’s upfront, transparent verification and automated refresh capabilities help reduce the time taken to check your AI research line-by-line. Our own domain experts quantified this time-savings systematically by measuring the time to verify an AI-assisted report properly, tracing every source and checking every claim. SPARK reduced the time required for this process from roughly 50 hours to about 20 minutes, with the same rigour. Another more qualitative signal for its effectiveness? Teams we had not built SPARK for began using it unasked, for executive briefings, portfolio analysis, and trend research.
The takeaway
The bet underneath all of this is that the missing piece was never a smarter model. AI research was already fast and convincing; what it lacked was a way to make any model’s work accountable, checkable as it runs, and honest as the facts evolve. The short version is that we built an AI to check our AI.


